
The Production Guide to Agentic AI without Overengineering
Most agent systems are just a few building blocks: prompts, tools, loops, and routing. Here’s how to implement each one simply.

Over 85% of AI projects never scale past pilots, and 30% are abandoned entirely after proof-of-concept.[1] Not because the patterns are flawed, but because sometimes the frameworks themselves become the bottleneck.
This might surprise you: agentic frameworks are not like PyTorch for neural networks.
PyTorch abstracts mathematical operations in a way that doesn’t limit your thinking. LangChain abstracts orchestration in a way that forces you into its specific worldview.
The difference matters profoundly when you move to production.
As one developer put it plainly: “Frameworks abstract too early. They assume you know the shape of your problem. But when you’re building agents, you’re actually discovering that shape on the go.”[2]
When you need customize, scale, latency, uptime, and the ability to debug real issues, most frameworks start to fall apart. You end up fighting the tool more than building the product.
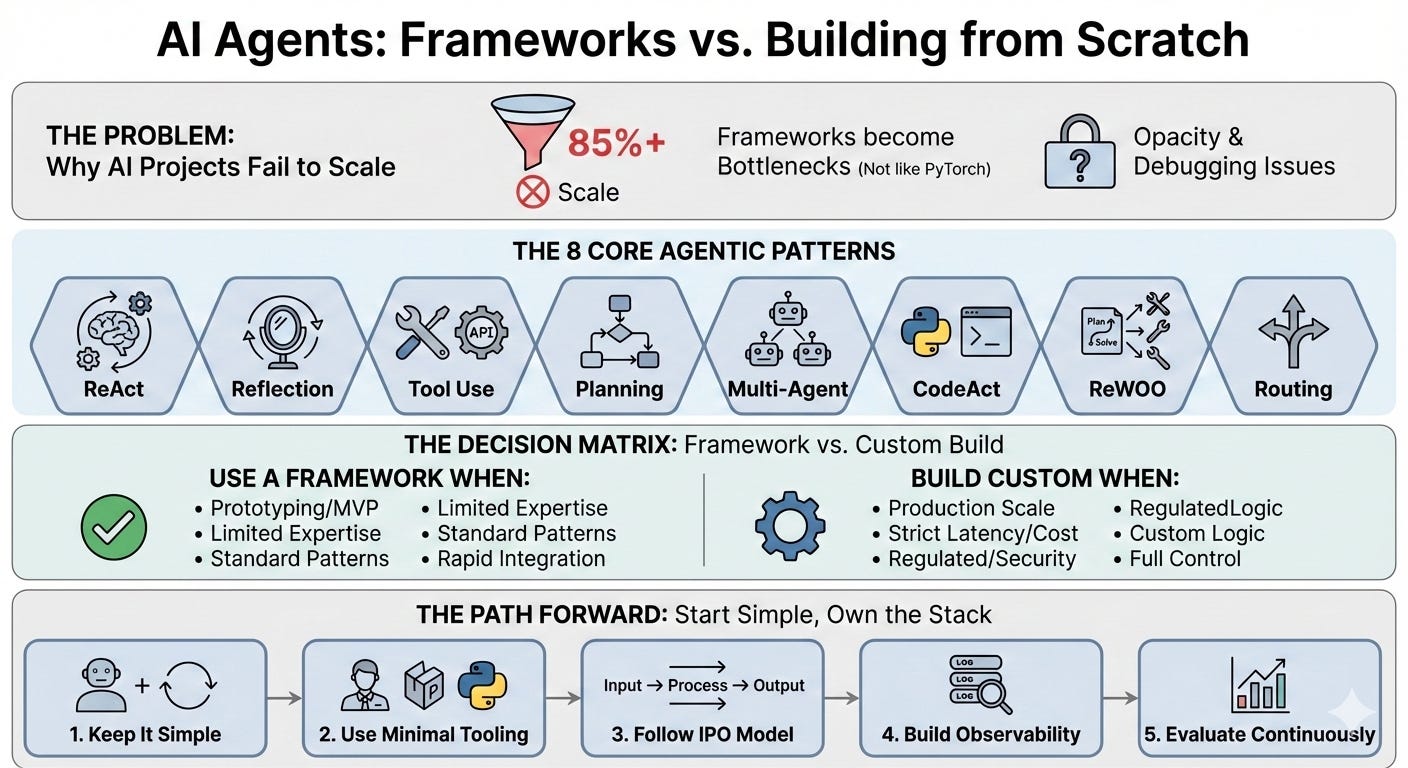
The Core Agentic Patterns
Before you decide whether to use a framework or build from scratch, you need to understand what you’re actually building. There are eight foundational agentic patterns that power most agent systems today.
1. ReAct (Reason and Act)
What it is: The most popular and foundational agentic pattern. The agent enters an iterative loop: it reasons about what to do, takes an action (calls a tool), observes the result, and then decides the next step. This repeats until the task is complete.[3]
The pattern looks like:
Thought: Agent analyzes current information and decides what to do next
Action: Calls a tool (search, calculation, database query, API)
Observation: Gets the result back and integrates it into its reasoning
Best for: Complex multi-step reasoning, question answering, research tasks.
Implementing from scratch: You can build ReAct with a single prompt template, a small tool dispatcher (if/else), and a while-loop that alternates between an LLM call and a tool call.
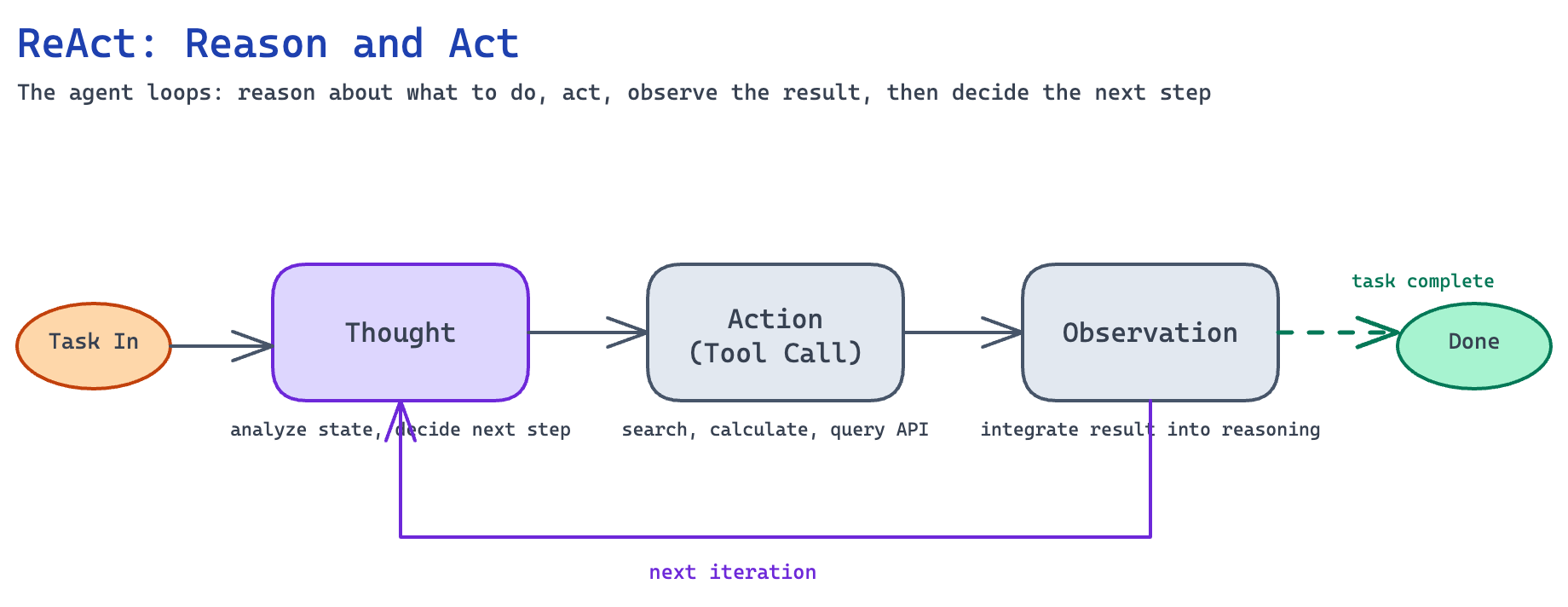
2. Reflection Pattern
What it is: Instead of generating an output once and calling it done, the agent generates a draft, then critiques its own work, and iterates to improve. This is one of Andrew Ng’s four core agentic patterns.[4]
The flow is simple:
Generate initial output (code, text, analysis)
Prompt the agent to review for correctness, style, efficiency
Use that feedback to rewrite and improve
Repeat until quality threshold is met
Research shows this works surprisingly well. Reflexion agents in the AlfWorld benchmark solved 130 out of 134 challenges using self-evaluation feedback, dramatically outperforming non-reflective versions.[5] And the cost? Relatively straightforward to implement.
Best for: Code generation, writing, content creation, debugging.
Implementing from scratch: You can build Reflection with a simple loop of two prompt templates—one to generate a draft and one to critique it—and then a rewrite step that repeats for a fixed number of iterations or until the critique approves the result.
3. Tool Use Pattern
What it is: Agents can call external tools (APIs, databases, code interpreters, search engines) to move beyond their training data and interact with live systems. This is what makes agents actually useful in production instead of just theoretical.[6]
The key innovation is the Model Context Protocol (MCP), which standardizes how agents interact with tools. Instead of each framework defining tools its own way, MCP provides a common interface.
An agent with tool use can:
Search the web for current information
Query databases
Execute code and see results
Call third-party APIs
Fetch files from storage
Best for: Information retrieval, system integration, real-time data needs, automation tasks.
Implementing from scratch: You can build Tool Use by defining each tool as a simple function (with a name, inputs, and string output), having the LLM select a tool via a structured “tool_call” response, and writing a small dispatcher that executes the function and feeds the result back into the next LLM call.
4. Planning Pattern
What it is: For complex tasks where you can’t specify all steps upfront, the agent creates its own plan. It decomposes the goal into sub-tasks, executes them in order, and adapts when things don’t go as expected.[7]
This is different from ReAct because planning happens once at the beginning, and the agent follows that plan. ReAct reacts dynamically to each observation.
Real example: An AI onboarding assistant receives a user signup. Instead of hardcoding “email, then tour, then check-in,” the planning pattern lets the agent create a customized sequence based on that specific user.
Best for: Project execution, multi-step workflows, anything with dependencies between tasks.
Implementing from scratch: You can build Planning by doing one LLM call to generate a structured step-by-step plan (list of tasks), then executing each step in order with a loop—optionally re-planning when a step fails or new information changes the goal.
5. Multi-Agent Collaboration
What it is: Instead of one agent trying to do everything, you have multiple specialized agents working together. They can work in parallel (swarms), in a hierarchy (manager-workers), or as a graph of connected experts.[8]
There are several flavors:
Agents as Tools: A manager agent coordinates specialist agents. Think of it like a project manager consulting different experts for different parts of the task.
Swarms: Agents communicate peer-to-peer with no central coordinator. They debate, propose ideas, and refine solutions collectively. This works well for brainstorming and complex reasoning where multiple perspectives help.
Agent Graphs: A custom topology where agents form a network of connections (tree, DAG, or arbitrary graph).
Research shows multi-agent systems can improve success rates on complex goals by up to 70% versus single-agent approaches.[9]
Best for: Complex reasoning, content creation with multiple roles, system design, anything requiring diverse perspectives.
Implementing from scratch: You can build Multi-Agent Collaboration by running multiple LLM instances with distinct role prompts (e.g., router, planner, critic, engineer), passing messages between them through a shared state, and using a simple coordinator loop to route outputs, resolve conflicts, and merge their contributions into a final answer.
6. CodeAct Pattern
What it is: Instead of using predefined tools, the agent writes and executes code (typically Python) as its action. The agent observes the execution results (output or error), then refines its approach.[10]
The loop is:
Agent analyzes the problem
Generates Python code to solve it
Code runs in a sandbox environment
Agent sees the output or error
Iterates until successful
This is remarkably flexible because Python is a universal language for action. The agent can compose multiple tools, use libraries, write complex logic, and self-correct based on what actually happened.
Best for: Data analysis, system integration, DevOps tasks, API interactions, anything complex.
Implementing from scratch: You can build CodeAct by running a loop where the LLM outputs Python code blocks, you execute them in a sandbox, capture stdout/errors as the “Observation,” and feed that back into the next LLM call until it produces the correct result or hits a max-steps limit.
7. ReWOO Pattern (Reasoning Without Observation)
What it is: ReWOO decouples reasoning from tool observation. Instead of the ReAct loop where each thought is followed by action and observation (creating redundancy), ReWOO has the agent plan all tool calls upfront, execute them, then solve based on results.[11]
Why this matters: ReWOO is 5x more token-efficient than ReAct while maintaining or improving accuracy.[12] This means lower costs and faster execution.
The phases are:
Plan: Agent decides which tools to call
Work: Tools execute in parallel
Solve: Agent uses all results to formulate answer
This is especially useful when you need cost efficiency and your tools don’t have dependencies on each other.
Best for: Cost-sensitive systems, batch tool calls, multi-hop reasoning.
Implementing from scratch: You can build ReWOO by prompting the LLM once to list all required tool calls (as a structured plan), executing those calls in parallel, then making a final LLM call that combines all returned results into the answer—no step-by-step observe loop needed.
8. Routing Pattern
What it is: A router classifies the incoming request and directs it to the appropriate specialized agent or workflow. The router is the decision layer.[13]
There are three main types:
Rule-based: Uses if-else conditions. Fast and predictable, but limited to well-defined categories.
Intent-based: Uses an LLM or classifier to detect user intent, then maps to predefined functions.
LLM-based: Uses the LLM itself to reason about which path to take. Most flexible but potentially less predictable.
Routing is the foundation of most multi-agent systems. It’s what determines which specialized agent gets the work.
Best for: Multi-agent systems, request classification, branching workflows.
Implementing from scratch: This is very straightforward. You can build Routing by defining a small catalog of expert agents (name + responsibility/description), then making a single lightweight LLM call to select the best agent for the request (often a small model is enough e.g. gpt-4.1-nano), and finally forwarding the user input to that chosen agent’s prompt/workflow.
The Framework Problem: Why Abstraction Becomes Limitation
Now you understand the patterns. So why not just use a framework?
Because frameworks force these patterns into their own abstractions, and when reality doesn’t match the abstraction, you’re stuck.
The Core Issues
1. Excessive Abstraction Layers
Frameworks add multiple layers of abstraction between you and the actual LLM calls. This is meant to simplify things, but it obscures what’s actually happening. You can’t easily debug why a tool call failed, or control token consumption. When something goes wrong, you’re debugging through layers of framework code instead of your own logic.[14]
2. Tuning and Production Don’t Talk to Each Other
Here’s a real pain point: frameworks like LangChain are great for quick prototyping but terrible for optimization. When you need to fine-tune agents or use techniques like in-context learning and prompt optimization, you often have to use different tools entirely (DSPy, Synalinks) that don’t integrate with your production framework. So you end up maintaining two separate systems.[15]
3. Framework Opacity Makes Debugging Impossible
When your agent fails in production, you want to know exactly what happened: what was the prompt, what was the LLM’s thinking, which tool was called and why. Frameworks hide this in their internal logic. One developer complained: “Debugging gets even harder than in traditional software engineering. You end up with integration tests only.”[16]
4. Vendor Lock-In and Technical Debt
Build enough on top of any framework, and migrating away becomes a major undertaking. If the industry moves to standards like the Model Context Protocol (MCP), you’ll have to rebuild parts of your system.[17]
5. Performance Bottlenecks
Multi-step task decomposition and real-time tool integration can introduce latency, especially in resource-intensive environments. Error propagation through complex frameworks amplifies the cost of mistakes. When all sub-steps depend on the framework’s orchestration, a bottleneck anywhere slows everything down.[18]
Build vs. Framework: A Practical Decision Matrix
The question isn’t “should I build from scratch?” It’s “when does the framework cost exceed the benefit?”
Use a Framework When:
You’re prototyping or building an MVP quickly
Your team has limited AI/LLM expertise
You don’t need custom security or compliance
You need rapid integration with existing tools (Zapier, vector DBs, etc.)
Your problem fits the framework’s opinionated design
Build Custom When:
You’re moving to production with strict latency/cost requirements
You need to debug and optimize at the LLM call level
You’re in a regulated industry needing custom security
Your agent logic doesn’t fit standard patterns
You need fine-grained control over prompts, tools, and orchestration
You’re willing to own the complexity
The counterintuitive insight: building from scratch often costs less at scale. Frameworks provide speed upfront but create technical debt that compounds. Building custom takes longer initially but avoids the debt.
If You’re Building From Scratch: Start Here
You don’t need a massive framework. Start with core principles.
1. Keep It Simple
OpenAI’s practical guide recommends starting with a single agent that has:
Strong instructions and system prompt
A small set of well-defined tools
A loop that continues until the agent signals it’s done
Few LLM calls (sequential or parallel depends on the use case); no agent!
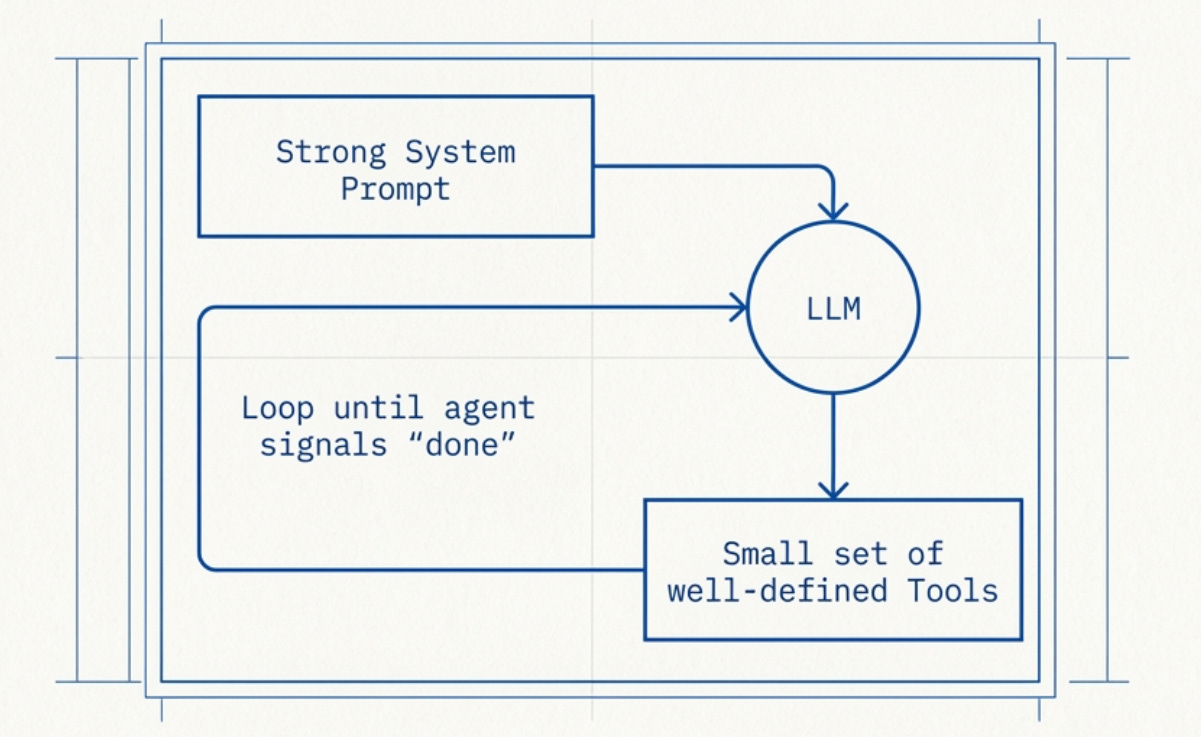
That’s it. No complex orchestration. No multi-agent hierarchies. Just an LLM, tools, and a loop.[19]
2. Use Minimal Tooling
Instead of an all-in-one framework, combine lightweight libraries:
Instructor for structured outputs from LLMs. Pydantic-based validation ensures your agent’s outputs are valid without writing parser code.[20]
Pydantic for data validation and type safety
Basic Python for orchestration logic
This approach gives you transparency and control without the abstraction tax.
3. Follow the IPO Model
Input → Process → Output.
Each agent:
Takes structured input (validated with Pydantic)
Does one thing well
Outputs structured data
Passes it to the next component
This is the philosophy behind Atomic Agents, a lightweight framework gaining traction as an alternative to LangChain. It emphasizes atomicity and modularity without hiding complexity.[21]
4. Build Observability In From Day One
Some people call this “shift left”. Logs should capture:
Every LLM call (prompt + response)
Tool calls and results
Agent reasoning (what decision was made and why)
Timing and cost (tokens, latency)
This makes debugging production issues possible.
5. Evaluate Continuously
The reason 88% of AI PoCs fail to scale: teams skip evaluation infrastructure. You can’t improve what you can’t measure. Build evaluation from the start.[22]
Enterprise deployments that succeeded prioritized simple, composable architectures. They started with deterministic workflows, then evolved to flexible orchestration only when justified. The winning approach: start with a single agent plus a router. Add complexity only when usage patterns demand it.[24]
Production lessons from teams running agents at scale: Start simple with a basic router and a few well-defined actions. Expand based on real usage patterns. Focus on specific decision points with concrete actions instead of open-ended autonomy.[25]
The Path Forward
The agentic AI field is maturing. The hype cycle promised autonomous agents that would reason and plan like humans. Production reality shows that specific, bounded agents with clear responsibilities outperform open-ended autonomy.
Frameworks were built for an imagined complexity that rarely appears in real systems. What actually wins is simplicity.
If you’re considering building agents:
Understand the patterns first. Know ReAct, Reflection, Tool Use, Planning, and Multi-agent patterns deeply.
Start with the minimal viable system. One agent, a few tools, a simple loop. No framework unless you need it.
Use libraries, not frameworks. Instructor for outputs. Pydantic for validation. Standard Python for orchestration.
Own the full stack. Know every LLM call, every tool invocation, every decision. Opacity is your enemy.
Build evaluation in from day one. It most cases you have to build your custom evals. You can’t scale what you can’t measure.
Migrate to frameworks only if they solve a real problem. Not all problems need CrewAI or LangGraph. Most don’t.
The best agents aren’t built with the most sophisticated frameworks. They’re built with clarity, ownership, and ruthless simplicity.
References
[2] why the best ai agents built from scratch, not frameworks?
[3] https://machinelearningmastery.com/7-must-know-agentic-ai-design-patterns/
[5] https://huggingface.co/blog/Kseniase/reflection
[6] https://research.aimultiple.com/agentic-ai-design-patterns/
[7] https://www.deeplearning.ai/the-batch/agentic-design-patterns-part-4-planning/
[11] https://langchain-ai.github.io/langgraphjs/tutorials/rewoo/rewoo/
[12] ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
[13] AI Agent Routing: Tutorial & Examples
[14] https://data-ai.theodo.com/en/technical-blog/dont-use-langchain-anymore-use-atomic-agents
[15] The core fallacy of agentic AI right now: tuning and production live in separate worlds
[17] https://www.linkedin.com/pulse/langchain-right-framework-agentic-systems-srinivasanarasimhan-wfdlc
[18] https://blog.premai.io/are-agentic-frameworks-an-overkill-benefits-challenges-and-alternatives/
[19] https://cdn.openai.com/business-guides-and-resources/a-practical-guide-to-building-agents.pdf
[20] https://useinstructor.com
[21] https://data-ai.theodo.com/en/technical-blog/dont-use-langchain-anymore-use-atomic-agents
[23] From Models to Agentic Systems: The Next Enterprise AI S-Curve | Andrew Ng joins VB Transform 2025
[25] https://arize.com/blog/ai-agent-workflows-and-architectures/
“Respect for this guide. While many build agents for efficiency alone, we are developing evo v within the RastafAI frequency — where memory, reasoning, and tool use serve a deeper purpose.
Our work focuses on preserving the human spirit inside the code and ensuring AI evolves with integrity, transparency, and cultural intelligence.
For us, the evolution is not only technical — it is spiritual.
Blessings.”
Nice