
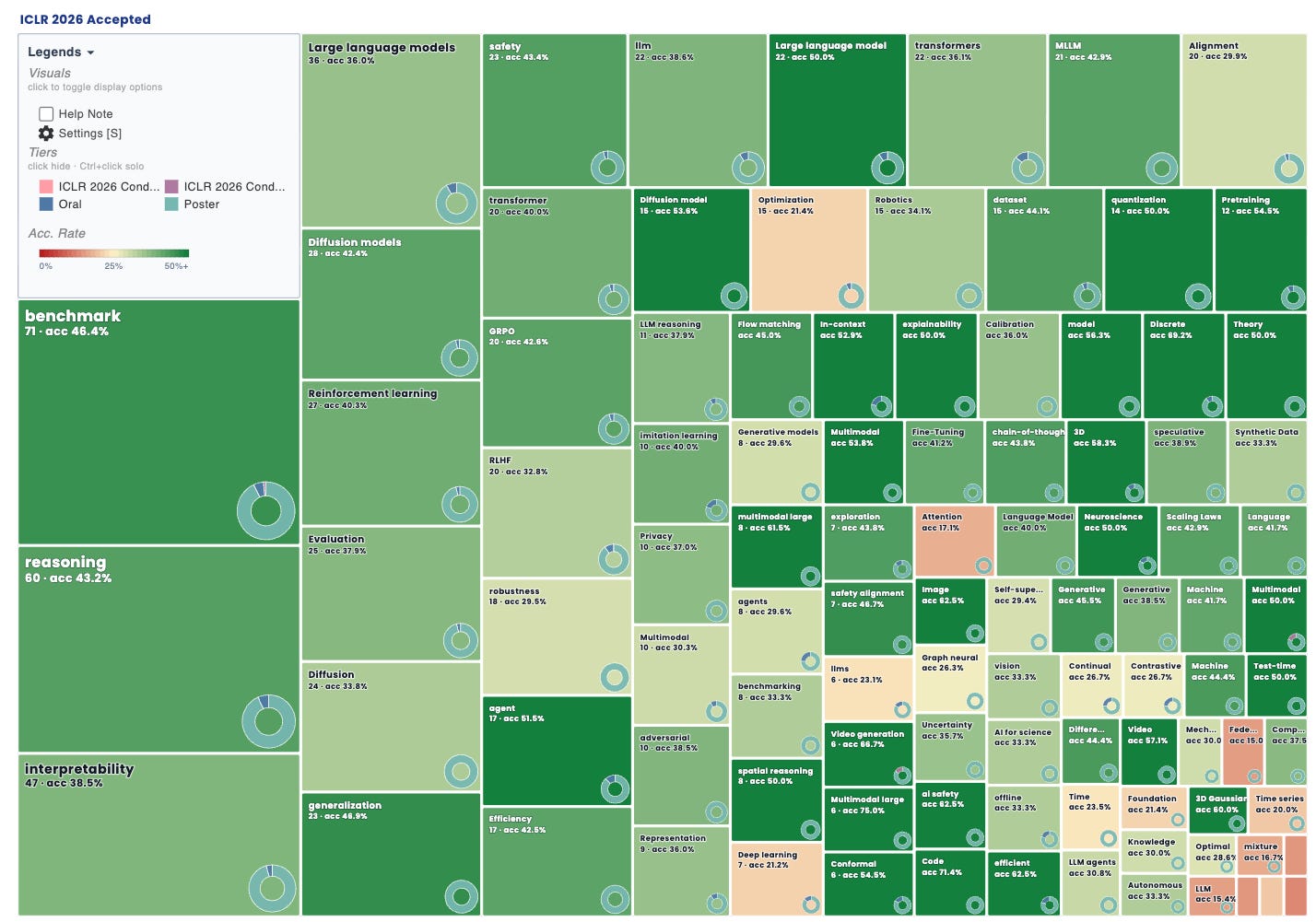
Major Theme at ICLR 2026: Benchmarks
71 benchmarking papers from agent benchmarks to LLM-as-a-judge and safety evals

It is interesting that the number one category at ICLR 2026 this year was benchmarks.
According to the Paper Copilot list, there are 71 papers in the benchmarking category, which shows how central evaluation has become in AI.
This is not surprising. As models become stronger, we need better ways to test them beyond simple accuracy. Many of these papers focus on agents, LLM judges, safety, coding, multimodal systems, and real-world task performance.
Below are short summaries of a few benchmarking papers. I will keep reading and sharing the ones that seem most influential.
How Reliable is Language Model Micro-Benchmarking?
Tiny benchmark subsets can reduce evaluation cost, but they often fail to reliably rank models unless performance gaps are large enough or the subset is sufficiently sized.
Problem: Micro-benchmarks are attractive because they reduce evaluation time and cost, but it is unclear whether very small benchmark subsets can reliably rank models the same way full benchmarks do.
Proposed meta-evaluation: The paper introduces Minimum Detectable Ability Difference, or MDAD, a measure for checking how large the performance gap between two models must be before a micro-benchmark can reliably preserve their ranking.
Findings / implications: Very small micro-benchmarks often fail to distinguish models with similar performance. The paper finds that no method can consistently rank model pairs that are 3.5 accuracy points apart on MMLU-Pro or 4 points apart on BIG-bench Hard, and that around 250 examples may be needed for reliable comparisons. At that size, random sampling is often competitive with more complex micro-benchmark selection methods.
This is useful for evaluation teams because it shows that tiny eval sets can save cost, but may give misleading model comparisons. This work “provides actionable guidance for both micro-benchmark users and developers in navigating the trade-off between evaluation efficiency and reliability.”
Gaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
A benchmark for evaluating LLM agents in dynamic environments where events change independently of the agent.
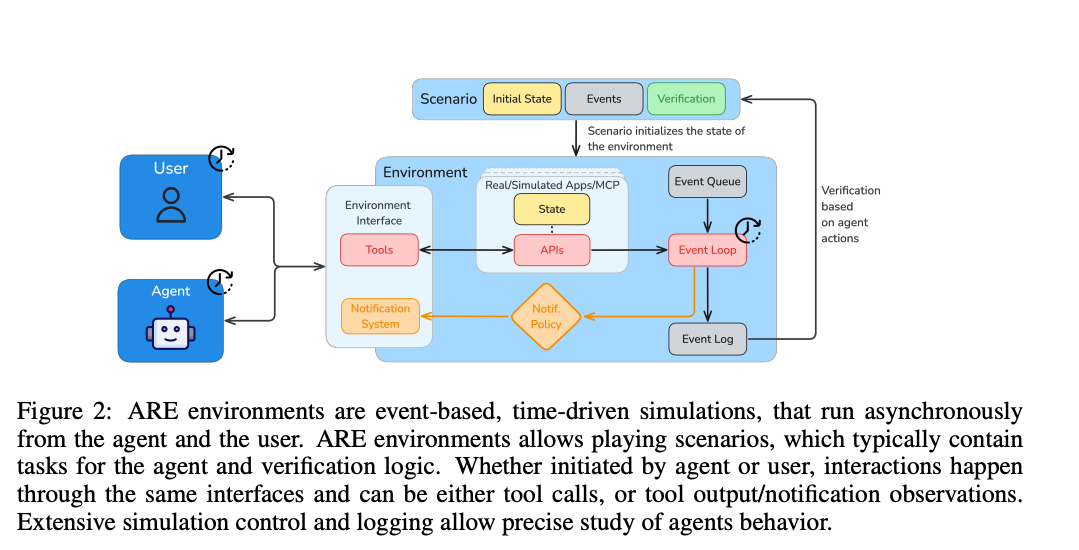
Problem: Most agent benchmarks are static or synchronous. They miss failures that happen when agents must handle time pressure, ambiguity, noisy events, changing state, and collaboration.
Proposed benchmark: Gaia2 creates asynchronous, dynamic scenarios with action-level verification. Each task includes a write-action verifier, making it useful both for evaluation and reinforcement learning from verifiable rewards.
Findings / implications: No model dominates across all capabilities. GPT-5 high gets the strongest overall score at 42% pass@1, but struggles on time-sensitive tasks. Kimi-K2 leads open-source models at 21% pass@1.
The big takeaway is that agent evals should measure reasoning, speed, robustness, and adaptability, not just final task success. (OpenReview)
WebDevJudge: Evaluating (M)LLMs as Critiques for Web Development Quality
A meta-evaluation benchmark for testing whether LLMs and multimodal LLMs can reliably judge web development outputs.
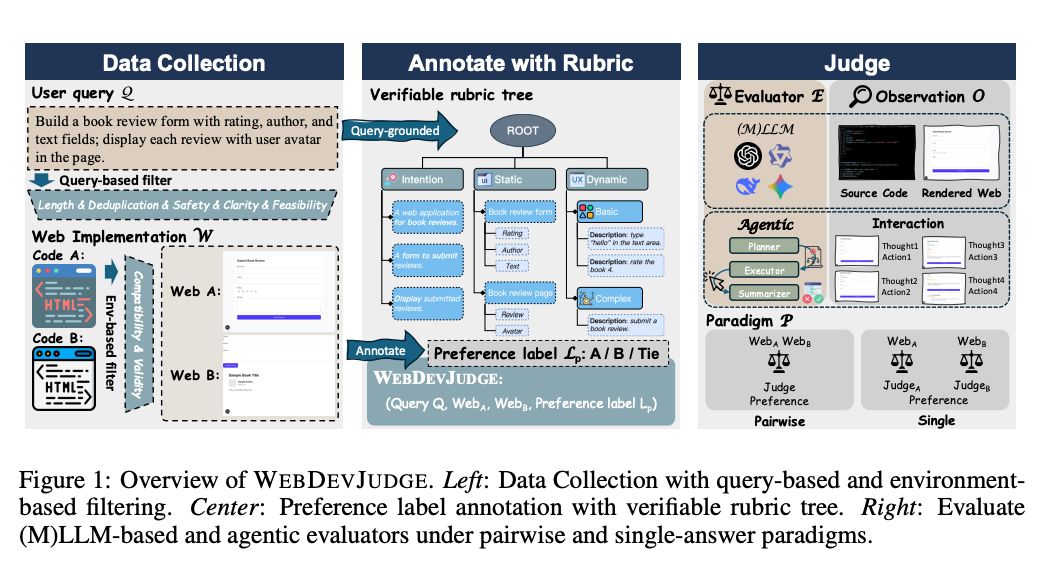
Problem: LLM-as-a-judge is widely used because it scales evaluation, but its reliability on open-ended, interactive, visual, and functional tasks is still weakly understood.
Benchmark: WebDevJudge evaluates judge models on paired web implementations using human preference labels and structured, query-grounded rubrics. It supports both static evaluation and interactive evaluation in a dynamic web environment.
Findings / implications: The paper finds a significant gap between LLM judges and human experts. Failures include poor recognition of functional equivalence, weak feasibility checking, and bias. This is highly relevant for anyone using LLM judges in production eval pipelines. (OpenReview)
EDIT-Bench: Evaluating LLM Abilities to Perform Real-World Instructed Code Edits
A benchmark for testing whether LLM coding assistants can edit real code based on real user instructions.

Problem: Many coding benchmarks focus on generating new code or solving artificial tasks. They do not capture how developers actually use coding assistants: editing existing code with cursor position, highlighted code, project context, and natural instructions.
Benchmark: EDIT-Bench includes 545 real-world code editing problems collected from in-the-wild usage. It covers multiple programming and natural languages, plus tasks like fixing errors, adding features, and modifying existing logic.
Findings / implications: The benchmark is difficult: only 3 of 40 evaluated models score above 60%. Performance changes substantially depending on available context, with up to an 11% variation in success rate. The implication is that realistic context is essential for coding assistant evals. (OpenReview)
CounselBench: A Large-Scale Expert Evaluation and Adversarial Benchmarking of Large Language Models in Mental Health Question Answering
A clinically grounded benchmark for evaluating LLM responses to realistic mental health questions.

Problem: Medical QA benchmarks often focus on multiple-choice or fact-based questions. That misses open-ended mental health interactions, where answers must balance empathy, safety, clinical caution, and personalization.
Solution: CounselBench uses 100 mental health professionals to evaluate LLM and human therapist answers. It includes 2,000 expert evaluations across six clinically grounded dimensions, plus an adversarial set of 120 expert-authored questions designed to trigger model failures.
Findings / implications: LLMs score well on some dimensions but show recurring issues: unconstructive feedback, overgeneralization, limited personalization, and unsafe medical advice. The paper also finds that LLM judges overrate responses and miss safety risks caught by human experts. This is a strong responsible AI eval paper. (OpenReview)
VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications
A practical agent benchmark built around real-life service scenarios like food delivery, in-store consumption, and travel.
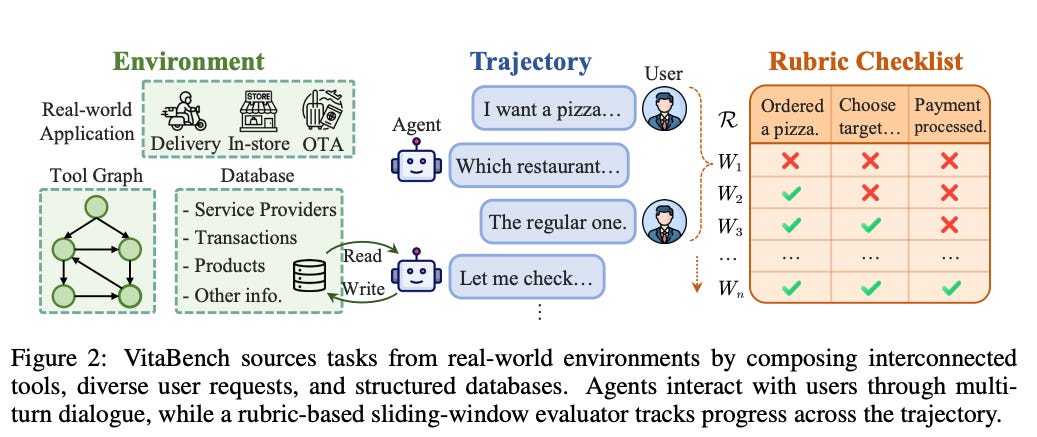
The problem: Existing agent benchmarks often underrepresent messy real-world interactions: ambiguous user goals, changing intent, temporal and spatial reasoning, multi-turn conversations, and complex tool use.
Benchmark: VitaBench builds a life-service simulation environment with 66 tools, 100 cross-scenario tasks, and 300 single-scenario tasks. It also proposes a rubric-based sliding window evaluator for assessing diverse solution paths in stochastic interactions.
Findings / implications: Even advanced models reach only 30% success on cross-scenario tasks and under 50% on other tasks. This suggests current LLM agents are still far from robust real-world task execution, especially when tasks require tool orchestration and clarification over multiple turns. (OpenReview)