
Fine-Tuning Small Language Models: From Dataset to Deployment
The full workflow: task selection, data, training, evaluation, and deployment

Free live webinar - Sat, Feb 7, 2026
Fine-tuning Small Language Models: dataset to deployment
📅 Sat, Feb 7, 2026
⏰ 9:00 AM PT (30 min)
💻Virtual (Zoom), sign up to join or watch the recording later.

Why small language models over bigger models?
In production, this is mostly an engineering tradeoff: risk, cost, latency, and operational control.
1. Privacy, compliance, risk
2. Cost and infrastructure efficiency
3. Latency and responsiveness
4. Agentic workflows and tool calling
5. Data residency and InfoSec constraints
6. Control, governance, and predictability
7. Edge, on-device, or offline capability
You might think fine-tuning an SLM and self-hosting it is a huge lift. Not anymore!
Today the tooling makes it much cheaper and just a few simple steps:
Prepare and format your dataset e.g Hugging Face Datasets)
Run a fast fine-tune (Unsloth, PEFT)
Make training repeatable and configurable (Axolotl, Hugging Face Trainer)
Export and package the model for inference (Transformers, safetensors)
Serve it behind an API for production use (vLLM, Ollama for local)
The 2026 question is ROI, not proof of concept. SLMs are one of the most practical ways to get there.
Here are some tooling and infrastructure that makes fine-tuning easier:
Training efficiency (fine-tuning speed and memory) e.g Unsloth
Training orchestration (repeatable training runs) e.g Axolotl
Serving (production-style inference) e.g vLLM
Which SLM use cases deliver high ROI?
Here are some high-ROI tasks that benefit most from fine-tuned SLMs, based on research and industry trends e.g. CES 2026:
Routing and query forwarding or gating (SLM first, LLM fallback): Use a small tuned model to decide “answer, retrieve, tool, or escalate” and only call a larger model when needed. This is often one of the fastest ROI wins because it reduces expensive calls.
Information extraction at scale: Domain-specific entity extraction and structured fields (claims, invoices, contracts, tickets) especially when you need consistent data schema.
Policy and compliance: Redaction, classification, and binary tasks e.g. “allowed or not allowed” checks where smaller or tiny models would just do the work.
On-device and embedded workflows: Mobile and edge scenarios where offline, privacy, and latency matter.
Standardized rewriting: Normalization, templated summarization, and formatting tasks are often better served by a smaller model than a large one. This is for use cases with many different data formats who want to standardize their data so it’s consistent and AI-ready.
How to approach fine-tuning small or tiny language models for real production tasks.
Start with a problem you want to solve using small or tiny language model. LLM would be overkilling.
Example: Structured extraction (high ROI, easy to measure): extract fields from invoices, claims, tickets, or contracts into a fixed JSON schema.
𝘛𝘩𝘦 𝘨𝘰𝘢𝘭 𝘪𝘴 𝘵𝘰 𝘵𝘶𝘳𝘯 𝘮𝘦𝘴𝘴𝘺 𝘵𝘦𝘹𝘵 𝘪𝘯𝘵𝘰 𝘢 𝘧𝘪𝘹𝘦𝘥 𝘑𝘚𝘖𝘕 𝘴𝘤𝘩𝘦𝘮𝘢. S𝘰 𝘵𝘩𝘪𝘴 𝘪𝘴 𝘯𝘰𝘵 𝘢 𝘤𝘩𝘢𝘵 experience. 𝘛𝘩𝘪𝘯𝘬 𝘭𝘪𝘬𝘦 𝘢 𝘧𝘶𝘯𝘤𝘵𝘪𝘰𝘯 𝘵𝘩𝘢𝘵 𝘳𝘦𝘵𝘶𝘳𝘯𝘴 𝘢 𝘫𝘴𝘰𝘯 𝘰𝘣𝘫𝘦𝘤𝘵 𝘢𝘭𝘭 𝘵𝘩𝘦 𝘵𝘪𝘮𝘦.
How to build the dataset?
Each training example should include:
• The raw input document
• The exact JSON output you want in production
Include cases that break the base model:
• Missing or optional fields
• Messy layouts and OCR noise
• Multiple dates or totals
• Ambiguous or conflicting values
𝗛𝗼𝘄 𝘁𝗼 𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝘁𝗵𝗲 𝗱𝗮𝘁𝗮
Use a simple instruction format:
• 𝗜𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻: what to extract and how
• 𝗜𝗻𝗽𝘂𝘁: the document text
• 𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗲: the target JSON
𝗛𝗲𝗿𝗲 𝗶𝘀 𝗮 𝘀𝗮𝗺𝗽𝗹𝗲 𝗱𝗮𝘁𝗮 𝗽𝗼𝗶𝗻𝘁 (instruction, input, output):
𝗜𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻
Extract invoice fields into the JSON schema.
𝗜𝗻𝗽𝘂𝘁 (𝗲𝘅𝗰𝗲𝗿𝗽𝘁)“…Thank you for your business.
Invoice A-1029 issued on Jan 14, 2026.
Payment terms: Net 30.
Line items omitted for brevity.
Total amount due USD 1,248.50.
Vendor: Acme Supplies…”
𝗢𝘂𝘁𝗽𝘂𝘁
{
invoice_id: "A-1029",
date: "2026-01-14",
vendor: "Acme Supplies",
total_amount: 1248.50
}

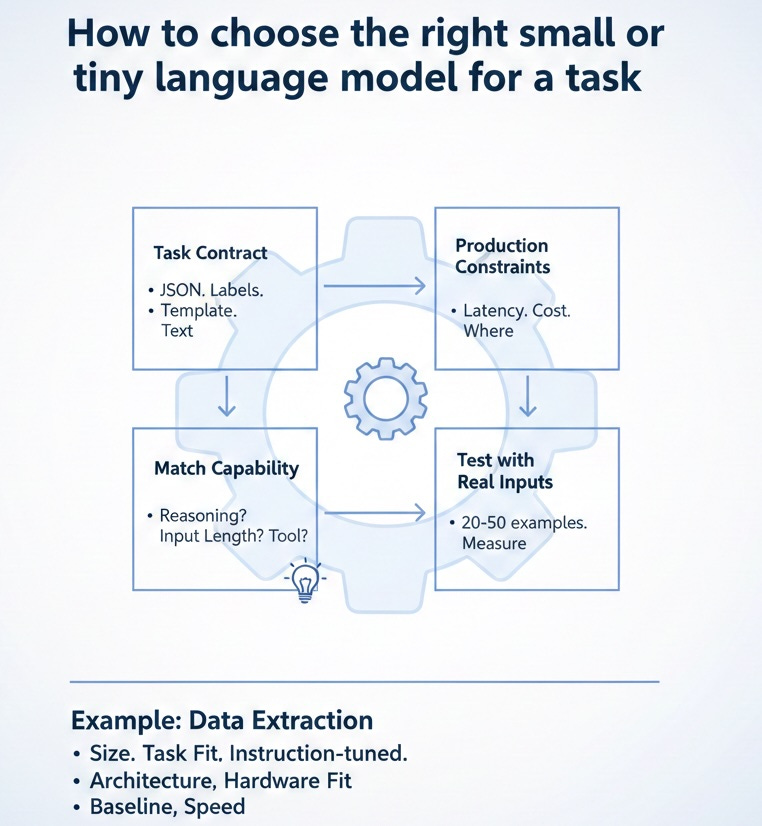
How to choose the right small or tiny language model for a task.
When selecting the right small language model (SLM) for fine-tuning,
I usually look at a few criteria:
➡️ Start with the task contract
What is the output?
JSON. Labels. Fixed template. Or free text?
If the output must be structured and consistent, we do not need a large model.
➡️ Define the production constraints
Define following metrics and make decision on:
Latency target
Throughput
Cost per request
Where it runs: cloud, on-prem, edge, local
These constraints eliminate many models immediately.
➡️ Match capability to the job
Ask simple questions:
Does it need reasoning or light pattern recognition?
How long is the input text?
Does it need tool calling or just transformation?
Most extraction, routing, and normalization tasks need consistent, structured outputs.
➡️ Test with real inputs early
Take 20–50 real examples and manually as ground truth. 𝘿𝙊 𝙉𝙊𝙏 𝙪𝙨𝙚 𝙇𝙇𝙈 𝙩𝙤 𝙜𝙚𝙣𝙚𝙧𝙖𝙩𝙚 𝙨𝙮𝙣𝙩𝙝𝙚𝙩𝙞𝙘 𝙙𝙖𝙩𝙖. You can use LLM, preferably reasoner models, to scale.
Run them through 2–3 candidate SLMs.
Measure:
Schema validity
Error types
Latency
Cost
Do this before any fine-tuning.
➡️ Here is an example: how I’d pick an SLM for the data extraction task.
For structured extraction, I’d filter models using:
• 𝗦𝗶𝘇𝗲: small enough to run where I need it (laptop, server, edge). Often sub 1B params.
• 𝗧𝗮𝘀𝗸 𝗳𝗶𝘁: simple, specific task. Fixed JSON output. Not broad chat.
• 𝗜𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻-𝘁𝘂𝗻𝗲𝗱: pick the instruction version so it follows commands reliably.
• 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲: decoder-style models work well for “text in → JSON out.”
• 𝗛𝗮𝗿𝗱𝘄𝗮𝗿𝗲 𝗳𝗶𝘁: fits comfortably in my available VRAM (often 16GB is a useful target).
• 𝗕𝗮𝘀𝗲𝗹𝗶𝗻𝗲 𝗮𝗯𝗶𝗹𝗶𝘁𝘆: even before tuning, it should produce something close to the right shape.
• 𝗦𝗽𝗲𝗲𝗱: for batch workloads, I choose the smallest model that meets accuracy and schema consistency.
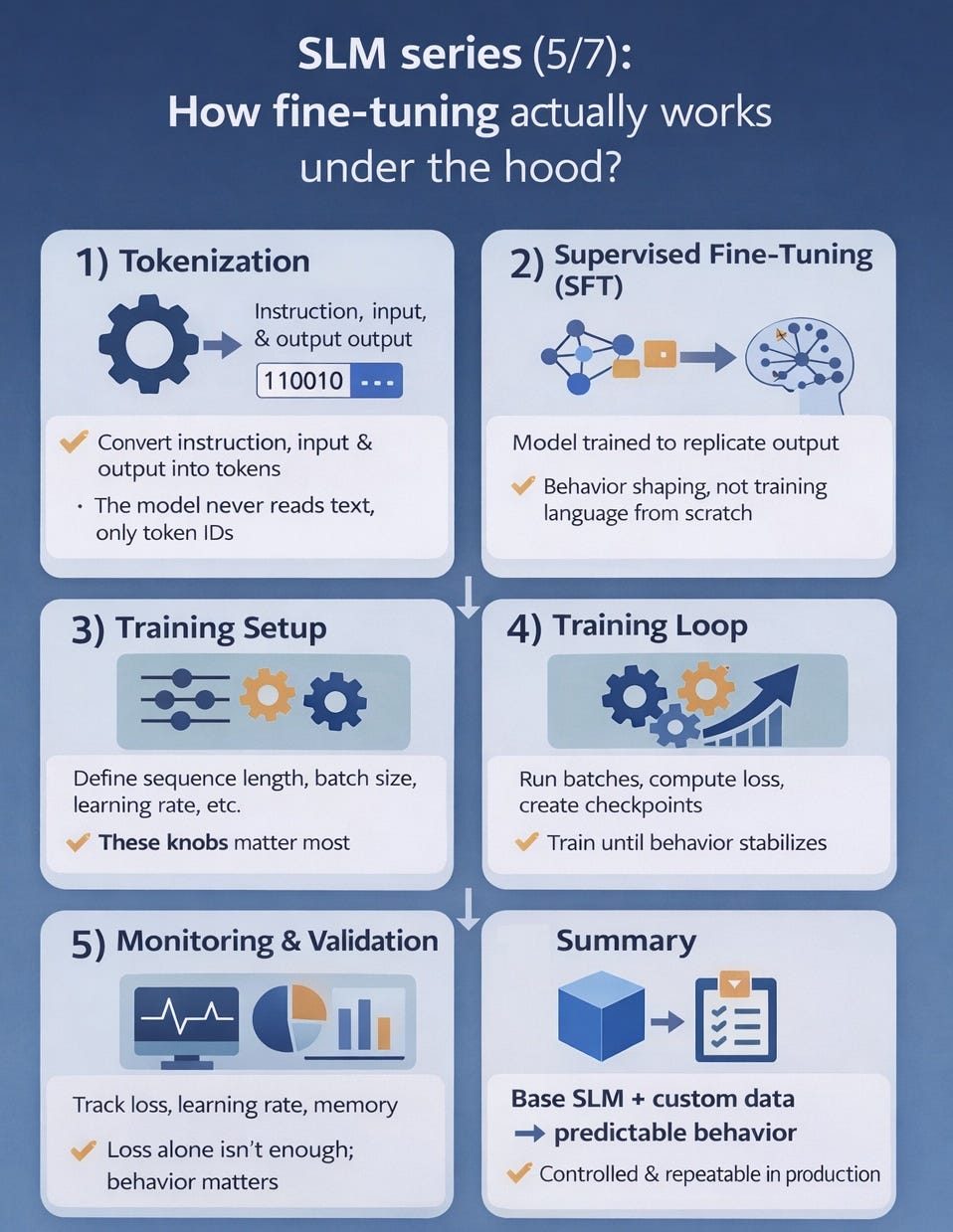
How fine-tuning actually works under the hood?
Previously I talked about 2 important components:
A 𝗯𝗮𝘀𝗲 𝗦𝗟𝗠 (for example, a sub-1B model) and a 𝘁𝗮𝘀𝗸 𝗱𝗮𝘁𝗮𝘀𝗲𝘁 (e.g. 1k labeled examples).
Here’s what happens under the hood during fine-tuning:
𝟭) 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻
The model never sees text. It sees token IDs.
Your tokenizer turns 𝗶𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻, 𝗶𝗻𝗽𝘂𝘁, 𝗮𝗻𝗱 𝘁𝗮𝗿𝗴𝗲𝘁 𝗼𝘂𝘁𝗽𝘂𝘁 into tokens.
Practical tip: output length matters.
Shorter, more consistent outputs reduce latency and cost at scale.
𝟮) 𝗦𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗲𝗱 𝗙𝗶𝗻𝗲-𝗧𝘂𝗻𝗶𝗻𝗴 (𝗦𝗙𝗧)
You show the model the input and the exact output you want.
Training pushes the model to assign higher probability to your target tokens.
𝟯) 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘀𝗲𝘁𝘂𝗽 (𝘁𝗵𝗲 𝗸𝗻𝗼𝗯𝘀 𝘁𝗵𝗮𝘁 𝗺𝗮𝘁𝘁𝗲𝗿)
A few settings dominate results and cost:
• 𝘀𝗲𝗾𝘂𝗲𝗻𝗰𝗲 𝗹𝗲𝗻𝗴𝘁𝗵 (how much context you train on)
• 𝗲𝗳𝗳𝗲𝗰𝘁𝗶𝘃𝗲 𝗯𝗮𝘁𝗰𝗵 𝘀𝗶𝘇𝗲 (how stable updates are)
• 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗿𝗮𝘁𝗲 (how much you adapt vs forget)
• 𝗽𝗿𝗲𝗰𝗶𝘀𝗶𝗼𝗻 𝗮𝗻𝗱 𝗺𝗲𝗺𝗼𝗿𝘆 𝘀𝘁𝗿𝗮𝘁𝗲𝗴𝘆 (what fits on your hardware)
𝟰) 𝗧𝗵𝗲 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗹𝗼𝗼𝗽
The trainer runs batches through the model.
𝗖𝗼𝗺𝗽𝘂𝘁𝗲𝘀 𝗹𝗼𝘀𝘀 against the target tokens.
𝗨𝗽𝗱𝗮𝘁𝗲𝘀 𝘄𝗲𝗶𝗴𝗵𝘁𝘀 (or adapters) step by step.
Then you checkpoint and evaluate on held-out examples.
𝟱) 𝗠𝗼𝗻𝗶𝘁𝗼𝗿𝗶𝗻𝗴
Watch for these metrics while training:
• Training vs validation loss diverging (overfitting)
• Learning rate schedule behavior (too fast or too slow adaptation)
• GPU memory and throughput (bottlenecks and stability)
Pro tip: Use Weights & Biases or TensorBoard to track runs in real time.
Pro tip: If you choose a tiny model (under 1B parameters) and run it locally, you can keep data private and reduce costs.
• Data stays inside your boundary
• Lower inference cost for high-volume workflows
• More predictable latency and throughput
• Easier to debug and iterate
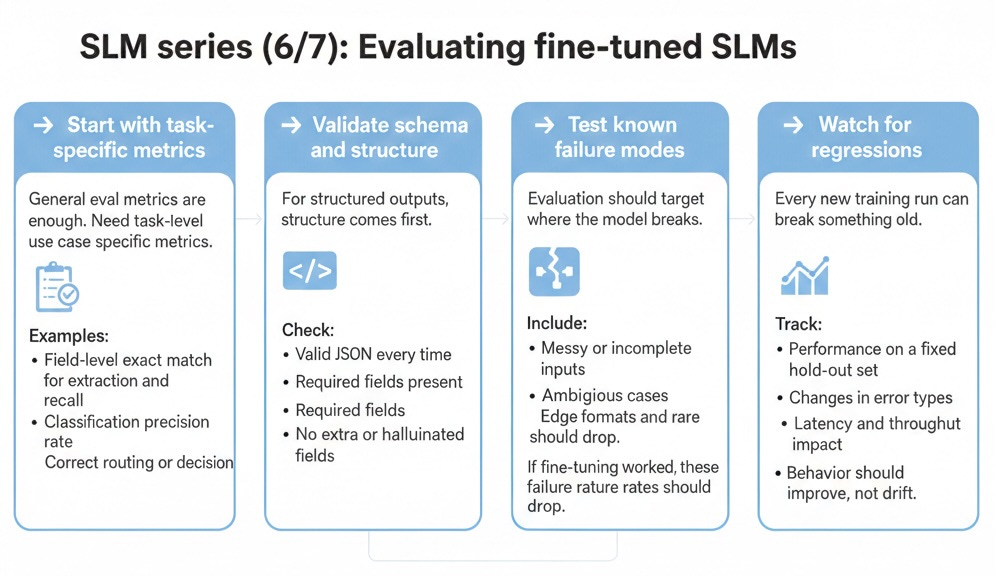
Evaluating fine-tuned SLMs for real production workloads.
This is how I decide if a fine-tuned model is ready for production.
➡️ Check task-specific metrics
General eval metrics are not enough. We need task-level, use case-specific metrics.
Examples:
• Field-level exact match for extraction
• Classification precision and recall
• Correct routing or decision rate
➡️ Validate schema and structure
For structured outputs check:
• Valid JSON every time
• Required fields present
• No extra or hallucinated fields
➡️ Test known failure modes
Evaluation should target where the model fails.
Include:
• Messy or incomplete inputs
• Ambiguous cases
• Edge formats and rare patterns
If fine-tuning worked, these failure rates should drop.
➡️ Watch for regressions
Every new training run can break something old.
Track:
• Performance on a fixed hold-out set
• Changes in error types
• Latency and throughput impact
• Behavior should improve, not drift.
➡️ Decide with thresholds
Set clear gates:
• Minimum schema validity
• Maximum error rate
• Acceptable latency and cost
If it meets the bar and requirements, then ship it.
If not, fix the data and retrain.
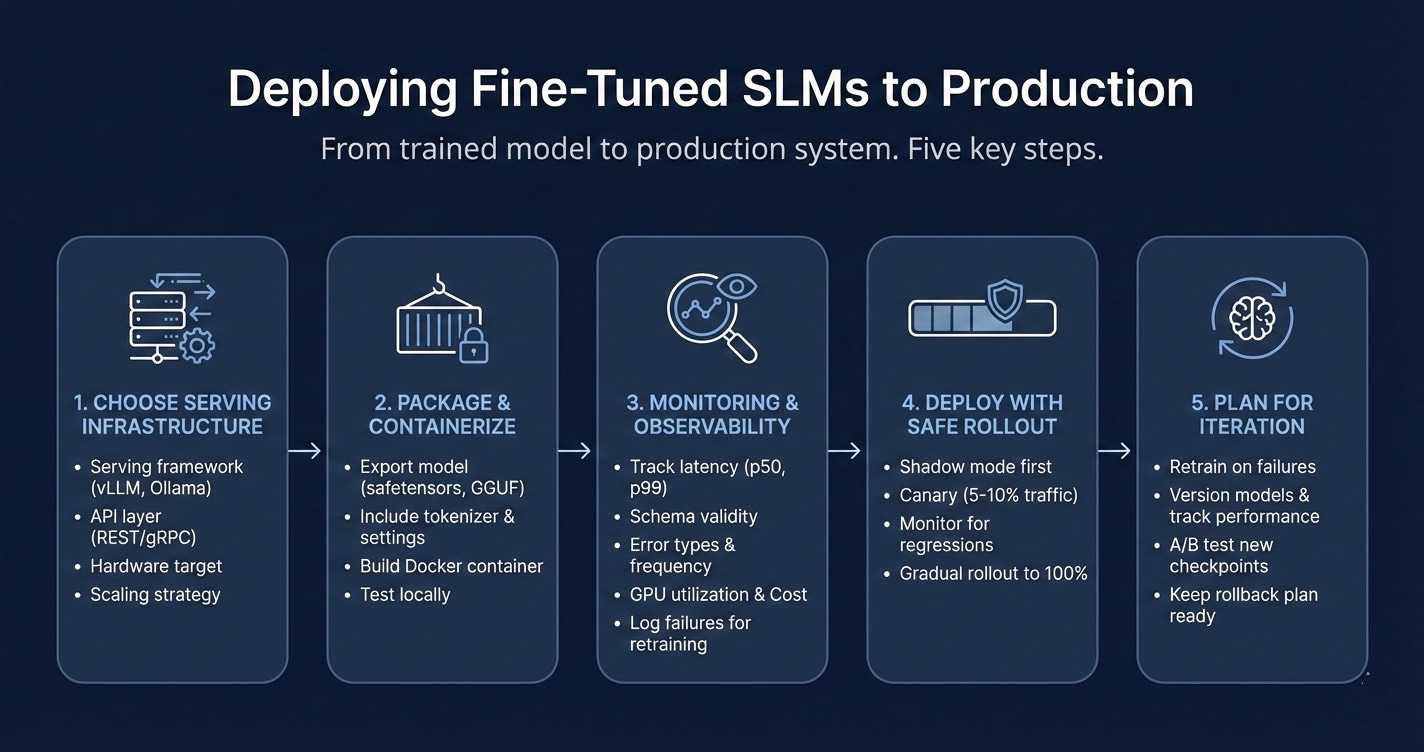
Deploying fine-tuned SLMs to production.
This is how you move from trained model to production system.
➡️ Choose your serving infrastructure
Production deployment needs:
Serving framework (vLLM for high throughput, Ollama for simplicity and local)
API layer (REST or gRPC endpoints)
Hardware target (cloud GPU, on-prem server, or edge device)
Scaling strategy (single instance, load balancing, or multi-region)
For structured extraction tasks, vLLM gives you the best throughput and latency.
➡️ Package and containerize
Export your fine-tuned model:
Save as safetensors or GGUF format
Include tokenizer config and generation settings
Build a Docker container with dependencies locked
Test locally before pushing to production
Packaging consistency prevents version drift and environment bugs.
➡️ Set up monitoring and observability
Track these in real time:
Request latency (p50, p95, p99)
Schema validity rate
Error types and frequency
GPU utilization and memory
Cost per request
Observability should be a shift left, meaning start from day 1. Log failures and edge cases for retraining.
➡️ Deploy with safe rollout
Use staged deployment:
Shadow mode first (run model, don’t act on output)
Canary to 5–10% of traffic
Monitor for regressions or failures
Gradual rollout to 100%
Never deploy directly to full production. Always validate behavior under real load.
➡️ Plan for iteration and updates
Production is not static:
Retrain on new failure cases
Version models and track performance over time
A/B test new checkpoints against baseline
Keep a rollback plan ready
Deployment SLM is never a one-time task. It always requires observability and monitoring to make it reliable and improving over time.
Free live webinar on fine-tuning SLMs
I’m presenting a free live webinar on Fine-tuning Small Language Models: dataset to deployment. If you find this useful consider signing up to join or watch the recording later.
Fine-tuning Small Language Models: dataset to deployment
📅 Sat, Feb 7, 2026
⏰ 9:00 AM PT (30 min)
💻 Virtual (Zoom)
🎟️ Free to join
Virtual (Zoom), sign up to join or watch the recording later.
Here is the link to the presentation.
https://docs.google.com/presentation/d/1T304huO7OGX7AML__dGDyqgtV0wPl16hCEerietJUcA