
Evaluating LLM based Applications
Methods for measuring meaning, reasoning, and reliability in LLMs

For many years, we relied on metrics like BLEU and F1 to judge model quality. These metrics were simple and practical. BLEU counted how many words and phrases in a model output matched a reference text.
This worked for tasks like machine translation or text classification. The problem is that these metrics were built for narrow problems. They were never designed for the kind of open ended generation we see in modern LLMs.
Today we use models to summarize, reason, write code, plan steps, answer questions, and act as agents. They cannot be measured by counting matching tokens.
For teams deploying LLMs in real products, what matters most is reliability in production.
The field is moving away from old token-matching metrics and toward methods that measure meaning, reasoning, and reliability. A recent survey found more than sixty different evaluation frameworks.
Models Need Semantic Checks, Not Token Counts
BLEU was built to check if a model repeated the right words. It does not check if the meaning is correct.
Take a simple example. An LLM is asked to summarize the climate benefits of renewable energy.
Human summary:
”Renewable energy reduces greenhouse gas emissions and helps slow climate change.”
Model summary:
”Wind and solar power lower CO₂ levels and reduce climate impacts.”
Both say the same thing. A human would score them almost the same. BLEU scores them low because the words do not match.
BLEU cannot see meaning. It only sees overlapping tokens.
This problem shows up everywhere:
Chat use cases: Many good responses do not share words with a reference answer.
Code generation: Two correct solutions can look different in style and variable names.
Scientific or legal tasks: What matters is reasoning and accuracy, not word overlap.
Token matching does not reflect real model quality. Modern evaluation must look at meaning, correctness, and reasoning. BERTScore matched human judgment much more closely. BLEU did not.
Benchmark Saturation and Data Contamination
Current frontier models like GPT-4o, Gemini 2.5, and Claude 3.5 routinely achieve 90-95%+ accuracy on established benchmarks like GLUE, SQuAD, and SuperGLUE.
These high scores might seem to indicate strong general capabilities. But research examining evaluation generalization reveals a complicating factor: many benchmark datasets appear in LLM training corpora, either through direct data inclusion or indirect web scraping.
Models can achieve high benchmark scores through memorization rather than genuine capability development.
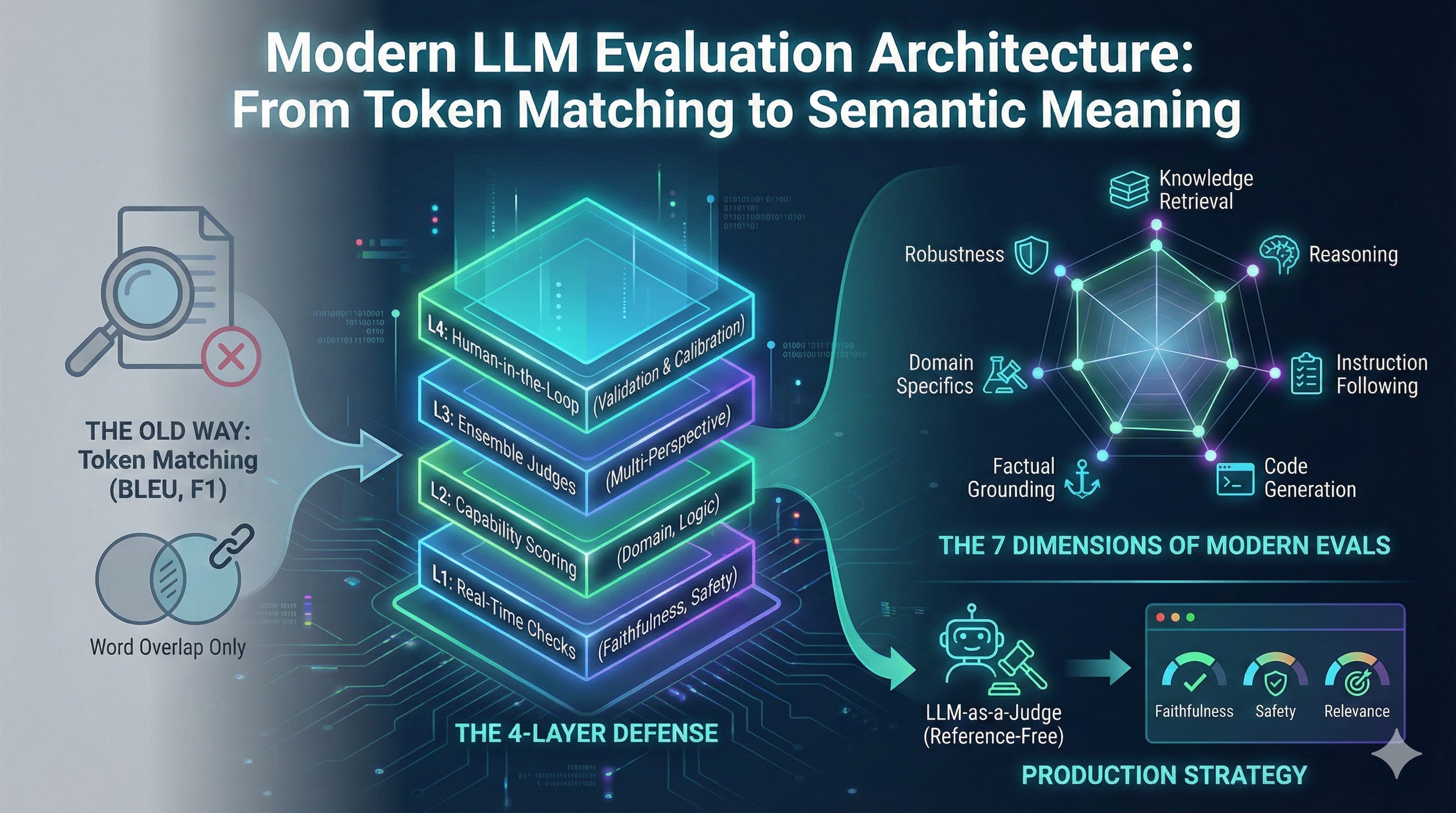
Seven Dimensions of Modern Evaluation
LLMs have multiple abilities that need separate evaluation. Recent research highlights seven core dimensions:
1. Knowledge Retrieval
Can the model access and apply factual information? Benchmarks like MMLU test general knowledge, while specialized benchmarks like ChemBench (2,788 chemistry question-answer pairs) and CURIE (covering materials science, quantum computing, and geospatial analysis) measure domain-specific knowledge.
Models often show substantial performance gaps between general knowledge and domain-specific knowledge.
2. Reasoning
Can the model construct valid logical chains? Mathematical reasoning benchmarks like AIME 2024 show clear separation: standard models achieve 15-20% accuracy, GPT-4-level models reach 78%, and newer reasoning-optimized models achieve 96.7% accuracy on AIME 2024.
3. Instruction Following
Research examining instruction-following capability shows it’s orthogonal to knowledge. A model might correctly answer “What is the capital of France?” (Paris) but fail when asked “Answer in UPPERCASE”—generating “Paris” instead of “PARIS”. These represent distinct capabilities.
4. Code Generation and Functional Correctness
Two implementations solving the same problem using different approaches should receive equivalent evaluation scores. Modern code evaluation uses execution-based validation and functional equivalence testing rather than token matching.
5. Factual Grounding
Fluent writing does not mean the content is true. Models must be checked for whether claims match the given source or context.
6. Domain-Specific Reasoning
Generic benchmarks fail to capture domain expertise. ChemBench shows that models performing well on MMLU often score substantially lower on chemistry-specific reasoning, despite strong general knowledge. Each specialized domain requires custom evaluation criteria.
7. Robustness and Consistency
Does model performance degrade when inputs are slightly perturbed? Under adversarial input or distribution shift, does reasoning remain sound? This dimension receives little evaluation.
Reference-Free Evaluation in Production
Reference free evaluation means judging model outputs without comparing them to a gold standard answer. Instead, the system looks at the <input, output> and a set of rules to decide if the response is correct, safe, or relevant.
Reference based methods work for tasks with a single right answer. But they do not scale. Creating high quality labels is slow, costly, and often impossible for expert domains.
Reference free methods solve this. They allow real time checks on every model output:
Faithfulness: Does the answer stay grounded in the given context.
Safety: Does the output avoid harmful, biased, or unsafe content.
Relevance: Does the response actually address the user request.
These checks require no reference dataset. They run continuously in production. When hallucinations increase or safety scores drop, the system can raise alerts instantly. This turns every user interaction into an ongoing evaluation signal.
See the research on reference-free evaluation frameworks.
LLM-as-a-Judge: Capability and Limitations
This approach became standard across frontier AI labs by 2024. However, research in 2025 revealed important constraints. Examining LLM judge robustness, researchers found:
Small stylistic variations in output cause false-negative rate swings up to 0.24 (24 percentage points)
Adversarial attacks can fool certain judges into misclassifying harmful content as safe
Judge performance degrades significantly under distribution shift
These findings suggest that LLM judges still have reliability limitations. The field is addressing this through ensemble approaches. Auto-Prompt Ensemble uses multiple independent judges with confidence weighting, improving judge reliability from 87.2% to 90.5% agreement with human experts. The approach combines:
Multiple independent judges providing diverse perspectives
Confidence-weighted aggregation rather than simple averaging
Continuous calibration against human feedback
Explicit uncertainty quantification when judges disagree
Domain-Specific Evaluation Frameworks
Generic benchmarks provide limited insight into domain-specific capability. ChemBench (May 2025) demonstrates this clearly. Comprising 2,788 chemistry question-answer pairs, ChemBench measures domain-specific reasoning: chemical reaction mechanisms, molecular properties, synthesis planning.
Models scoring 85%+ on MMLU often score <60% on ChemBench. The performance gap reflects that domain-specific expertise and general knowledge are largely orthogonal.
Google’s CURIE benchmark (June 2025) extends this approach across multiple scientific domains: materials science, condensed matter physics, quantum computing, geospatial analysis, biodiversity, protein structure. Rather than generic metrics, CURIE employs discipline-specific evaluation criteria developed with domain experts.
For organizations deploying LLMs in specialized fields—healthcare, legal services, materials science, finance—domain-specific evaluation is essential. Generic benchmarks provide false confidence; domain-specific assessment reveals actual capability.
Building Evaluation Systems in Practice
Organizations implementing modern evaluation systems typically structure them in layers:
Layer 1: Reference-Free Real-Time Metrics Every model output receives real-time assessment on dimensions like faithfulness, safety, relevance, and format compliance. These metrics require no reference annotations and operate at millisecond latency.
Layer 2: Capability-Based Evaluation Rather than single metrics, evaluation assesses multiple orthogonal capabilities: domain knowledge, reasoning validity, instruction adherence, safety alignment, robustness under perturbation. Each capability scores independently.
Layer 3: Ensemble Judgment with Calibration Multiple independent judges evaluate outputs with confidence estimates. Results aggregate using confidence weighting. Continuous validation against human expert feedback recalibrates judge reliability.
Layer 4: Continuous Monitoring Metrics stream continuously. Threshold violations and distribution shifts trigger alerts. Performance degradation activates escalation workflows. Evaluation is ongoing, not periodic.
The Human Validation Requirement
BLEU requires no domain knowledge—it counts tokens regardless of whether they make sense. But evaluating medical reasoning, legal arguments, chemical synthesis planning, or materials properties requires validators with relevant expertise.
For organizations deploying LLMs in high-stakes domains, this means:
Automated evaluation flags concerning outputs
Domain experts validate flagged cases
Results recalibrate automated systems
The process repeats continuously
This is labor-intensive, but necessary. The alternative is confident deployment of systems whose actual performance remains unknown.
Practical Implementation Path
For organizations currently evaluating LLMs:
Immediate actions:
Check if your current evals still depends on token-matching.
Identify domain-specific capabilities that generic benchmarks fail to measure.
Implement reference-free metrics for production assessment
Near-term:
Develop multidimensional evaluation across 3-5 capability dimensions
Establish baseline human performance for comparison
Build reference-free evaluation pipelines for production traffic
Medium-term:
Implement ensemble judges with confidence weighting
Establish human validation loops for metric calibration
Deploy continuous monitoring for metric degradation
Longer-term:
Develop or adopt domain-specific benchmarks
Check that benchmark scores match real world outcomes.
Test robustness with adversarial cases and distribution shifts.
Future Directions and Open Area
Recent research continues refining this approach:
Addressing evaluation generalization remains an active area. Research into adaptive evaluation methods and continuous benchmarking is ongoing.
Research on judge robustness continues examining how to build reliable evaluators that resist distribution shift and adversarial manipulation.
Domain-specific evaluation frameworks are expanding across more specialties as organizations recognize the inadequacy of generic benchmarks.
References and Further Reading
Research on Evaluation Frameworks:
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review – Taxonomy of 60 evaluation benchmarks
Toward Generalizable Evaluation in the LLM Era – Beyond static benchmarks
Know Thy Judge: On the Robustness Meta-Evaluation of LLM Safety Judges – LLM judge limitations
Benchmark Development:
ChemBench – Domain-specific chemistry evaluation (Nature, 2025)
CURIE: Scientific Domain Evaluation – Multi-domain assessment (Google, June 2025)
AIME Mathematical Reasoning – Reasoning capability assessment
Practical Tools and Frameworks:
BERTScore: Beyond Token-Matching Evaluation – Semantic evaluation metrics
Auto-Prompt Ensemble for LLM Judges – Reliable ensemble approaches
LLM Observability Platforms 2025 – Production monitoring tools
Reference-Free LLM Evaluation – Evaluation without ground truth